

Interrogez n’importe quel administrateur système ou expert réseau sur les temps d’arrêt, et ils vous diront probablement que c’est « tout ce qui peut mal tourner dans un système au moment précis où il devrait fonctionner de manière optimale ».
Étant donné que les organisations dépendent aujourd’hui fortement de la technologie et des processus numériques, de nombreuses choses peuvent se produire en cas de panne du système, en particulier quelques minutes avant un événement important.
Selon le rapport annuel d'analyse des pannes 2023 , 60 % des organisations ont été confrontées à une sorte de panne ou de temps d'arrêt au cours des trois dernières années. Pour rappel, le coût des temps d'arrêt est estimé à environ 9 000 dollars par minute, 98 % des entreprises affirmant qu'une seule heure de temps d'arrêt leur coûte environ 100 000 dollars.
Pour lutter efficacement contre les temps d'arrêt, les organisations s'appuient sur deux KPI clés de gestion des incidents : le temps moyen de réparation (MTTR) et le temps moyen de détection (MTTD). Même si leurs acronymes peuvent sembler similaires, leurs rôles dans le cycle de vie de la gestion des incidents sont distincts.
MTTD est essentiellement le temps nécessaire pour détecter un problème, tandis que MTTR nous indique combien de temps il faut pour le réparer. Ces deux mesures constituent le cœur de tout processus de gestion des incidents .
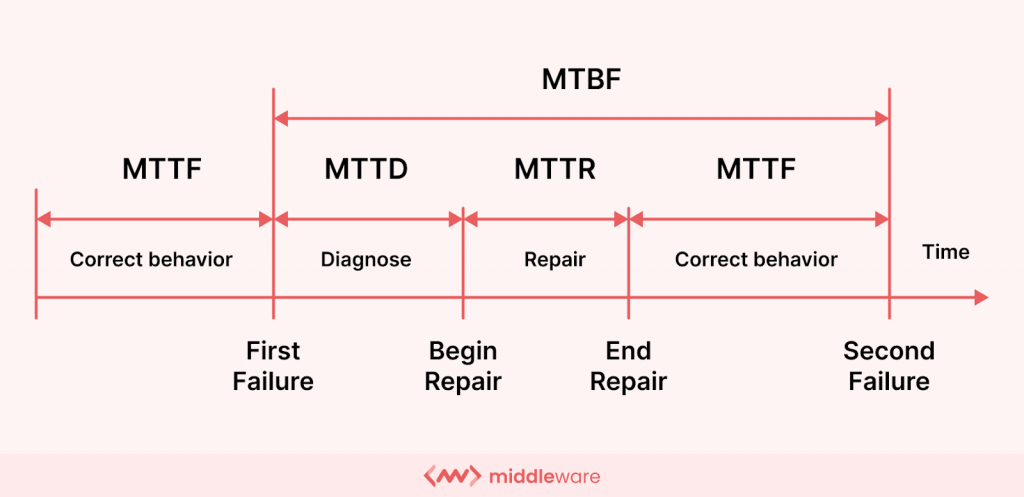
En utilisant ces mesures de manière stratégique, les organisations peuvent identifier et diagnostiquer la cause première de toute panne et réduire le temps nécessaire à sa réparation. Pour comprendre cela en profondeur, explorons ces métriques et les différences critiques entre MTTR et MTTD.
Qu’est-ce que le MTTD ?
Commençons par comprendre le premier KPI crucial, le temps moyen de détection (MTTD). MTTD signifie le temps moyen nécessaire pour identifier un incident après qu'il se soit réellement produit dans votre infrastructure informatique. Il est calculé à partir du moment où le système subit une panne ou une panne et du temps nécessaire pour détecter ou diagnostiquer complètement le problème.
Cette mesure reflète essentiellement l’efficacité de vos systèmes de surveillance et d’alerte à détecter les problèmes avant qu’ils ne se transforment en problèmes majeurs. Un MTTD inférieur se traduit par une détection plus rapide des problèmes, permettant à votre équipe de prendre des mesures rapides et de minimiser les temps d'arrêt.
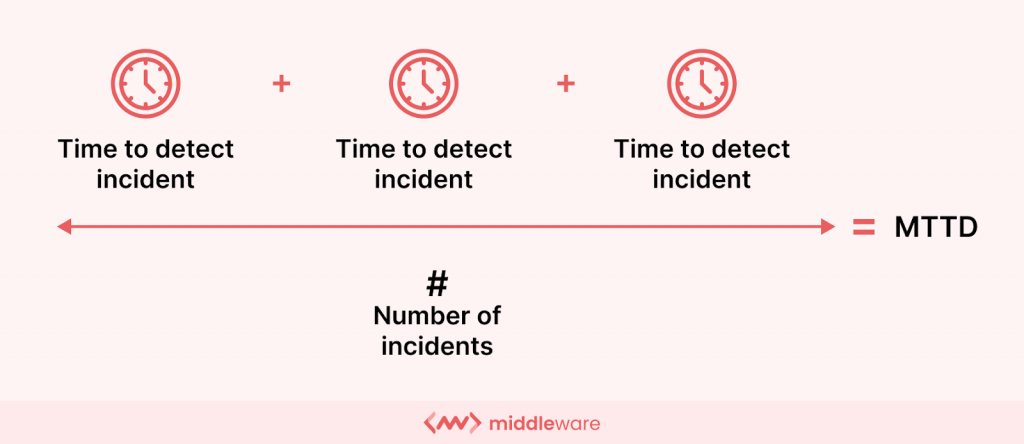
Pour calculer le MTTD, vous pouvez utiliser la formule suivante :
MTTD = (la somme de tous les temps de détection d'incidents) / (le nombre total d'incidents signalés au cours de cette période)
Par exemple, si le nombre total d'incidents dans un mois est de 5 et que le temps total pour détecter l'incident est de 251 minutes, le MTTD sera de 251/5 = 50,2.
Le MTTD est crucial pour la détection et la gestion des incidents et est influencé par les facteurs suivants :
- Capacités de surveillance : des outils de surveillance complets qui capturent un large éventail de métriques et de journaux du système sont essentiels pour la détection précoce des anomalies.
- Configuration des alertes : des alertes configurées efficacement, avec des seuils de notification clairs et des canaux appropriés, garantissent une sensibilisation rapide aux problèmes potentiels.
- Corrélation des données : la capacité de corréler les données provenant de diverses sources permet d'obtenir une vue globale de l'état du système et d'identifier plus rapidement la cause première des problèmes.
En utilisant une plateforme d'observabilité unifiée et en temps réel telle que Middleware , les organisations peuvent réduire considérablement le MTTD. Cette plate-forme doit centraliser la collecte de données de tous vos systèmes et applications, fournissant un tableau de bord unique pour les systèmes de surveillance. Cela vous aide à découvrir les menaces et les modèles potentiels avant qu'ils n'aient un impact considérable, en déclenchant même des déclencheurs pour informer votre équipe des activités ou fluctuations suspectes.
La détection des incidents à temps permet à vos équipes de gestion des incidents de résoudre les problèmes avant qu'ils n'aient un impact sur l'entreprise. De même, les temps d’arrêt peuvent être détectés en temps réel et diagnostiqués plus rapidement.
Qu’est-ce que le MTTR ?
Une fois qu’un problème ou un temps d’arrêt est efficacement diagnostiqué, nous arrivons à la prochaine mesure cruciale : le temps nécessaire pour réparer ou résoudre ce problème. Ceci est calculé à l’aide du temps moyen de réparation (MTTR).
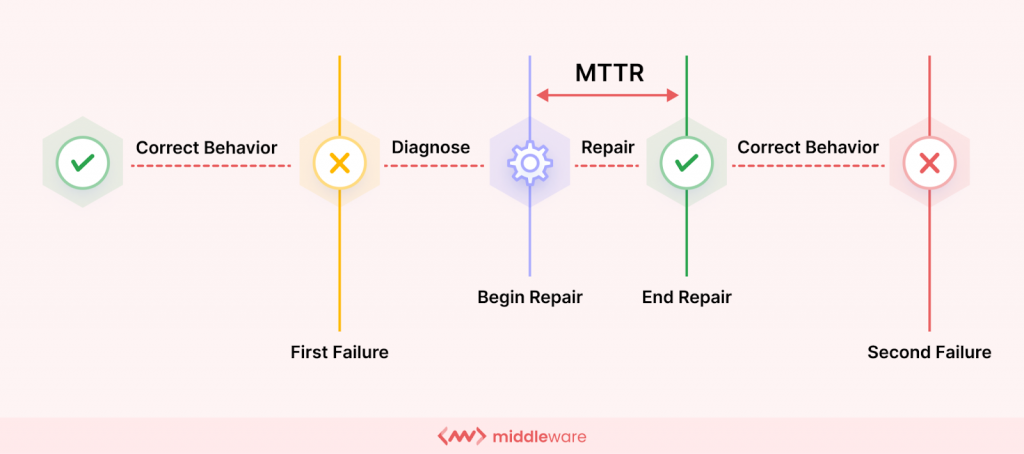
Le MTTR, également appelé temps moyen de résolution ou de récupération, mesure le temps moyen nécessaire pour diagnostiquer et résoudre un incident après sa découverte.
Cette métrique reflète essentiellement l’efficacité de vos processus de dépannage et de résolution. Un MTTR inférieur signifie un temps de récupération plus rapide, minimisant ainsi l'impact des temps d'arrêt sur vos opérations commerciales.
Il peut être calculé à l'aide de la formule :
MTTR = Temps total pour résoudre tous les incidents / Nombre d'incidents
Où,
- Temps total pour résoudre tous les incidents : cela représente le temps cumulé passé à résoudre tous les incidents dans un délai spécifique (par exemple, une semaine, un mois ou un trimestre).
- Nombre d'incidents : Désigne le nombre total d'incidents rencontrés sur la période choisie.
Les facteurs suivants influencent le MTTR :
- Complexité technique : les problèmes système complexes prennent naturellement plus de temps à diagnostiquer et à résoudre que les problèmes plus simples.
- Expertise de l’équipe : une équipe compétente et expérimentée peut identifier et résoudre les problèmes plus rapidement qu’une équipe aux connaissances limitées.
- Disponibilité des ressources : les outils et ressources facilement disponibles rationalisent le processus de dépannage.
- Procédures standardisées : des protocoles de réponse aux incidents clairement définis garantissent une collaboration efficace et minimisent les pertes de temps.
Pour réduire le MTTR, les organisations peuvent investir dans un outil de surveillance proactif , qui leur permet de surveiller toute leur infrastructure informatique et d'identifier les menaces potentielles avant qu'elles ne dégénèrent en problèmes importants.
Si le problème ne peut pas être diagnostiqué à un stade précoce, les équipes de gestion des incidents peuvent agir rapidement et prendre les mesures appropriées pour le résoudre ou le réparer avant qu'il n'ait un impact plus important.
En se concentrant sur ces aspects, les organisations peuvent réduire considérablement le MTTR et minimiser les perturbations causées par les pannes du système.
MTTR vs MTTD : quelle métrique est la plus importante ?
En termes simples, les deux comptent ! En effet, les deux KPI sont essentiellement corrélés. Plus rapidement votre équipe peut détecter et diagnostiquer un problème, plus le MTTD est faible. Et en identifiant les problèmes plus rapidement grâce à un diagnostic précis, vos équipes peuvent les résoudre efficacement, ce qui se traduit par un MTTR amélioré.
Traditionnellement, réduire le MTTR (Mean Time to Repair) et le MTTD (Mean Time to Detect) était un exercice d’équilibre. Les efforts visant à améliorer la détection des problèmes (MTTD) reposaient souvent sur la génération d'un volume élevé d'alertes, ce qui pouvait submerger les équipes et ralentir le processus de résolution (MTTR).
de Middleware Cependant, la plate-forme d'observabilité innovante comble cette lacune en offrant une suite robuste de fonctionnalités conçues pour traiter simultanément les deux mesures.
Comment réduire le MTTR et le MTTD à l'aide d'un middleware ?
Voici comment le middleware permet aux organisations de réduire considérablement le MTTR et le MTTD :
Tableau de bord unifié
Le middleware fournit un tableau de bord central qui offre une vue consolidée en temps réel de toutes les métriques, journaux , traces et événements de votre système. Cela élimine le besoin de basculer entre des outils disparates, permettant à votre équipe d'identifier rapidement les anomalies et les problèmes potentiels.
Journaux et traces
Le middleware permet aux utilisateurs d'explorer des métriques et des traces spécifiques associées à un problème identifié. Cette visibilité granulaire permet une compréhension plus approfondie du problème et facilite un dépannage plus rapide.
Notifications d'alerte en temps réel
Le middleware permet la configuration d' alertes intelligentes qui priorisent les problèmes critiques et fournissent des notifications riches en contexte. Cela garantit que votre équipe reçoit des informations exploitables, lui permettant ainsi de se concentrer en premier sur la résolution des problèmes les plus importants.
Base de connaissances centralisée
Le middleware facilite la création et la maintenance d'une base de connaissances centralisée où les incidents passés et leurs résolutions sont documentés. Cela permet aux équipes de tirer les leçons des expériences précédentes et de résoudre plus rapidement des problèmes similaires à l’avenir.
Essentiellement, le middleware agit comme un multiplicateur de force pour votre équipe informatique. Le tableau de bord unifié et les fonctionnalités avancées de corrélation des données permettent une détection plus rapide des problèmes (réduction du MTTD).
Une fois qu'un problème est identifié, l'analyse des métriques et des traces, associée à des alertes intelligentes, rationalise la résolution (réduction du MTTR). Cette approche holistique garantit que votre équipe est prête à relever tout défi qui se présente, en minimisant les temps d'arrêt et en maximisant la disponibilité du système.
Conclusion
L'optimisation du MTTR et du MTTD est une quête continue pour toute organisation qui s'efforce d'obtenir des performances système optimales . En comprenant les nuances de ces mesures et en mettant en œuvre les stratégies appropriées, vous pouvez réduire considérablement les temps d'arrêt et garantir un processus de réponse aux incidents plus efficace.
Les outils d'observabilité de bout en bout comme le Middleware n'offrent pas seulement une plate-forme ; ils favorisent une approche proactive de la santé du système. Grâce à ses fonctionnalités d'observabilité complètes, Middleware permet à votre équipe d'identifier les problèmes potentiels avant qu'ils ne dégénèrent en incidents majeurs.
Cette approche proactive minimise l'impact des temps d'arrêt et favorise une culture d'amélioration continue au sein de vos opérations informatiques.