
")
Qu’est-ce que la reconnaissance d’images IA ?
L'IA de reconnaissance d'images a pour tâche d'identifier les objets d'intérêt dans une image et de reconnaître à quelle catégorie l'image appartient. La reconnaissance d'images, la reconnaissance de photos et la reconnaissance d'images sont des termes utilisés de manière interchangeable.
Lorsque nous voyons visuellement un objet ou une scène, nous identifions automatiquement les objets comme différentes instances et les associons à des définitions individuelles. Cependant, la reconnaissance visuelle est une tâche très complexe à réaliser pour les machines, nécessitant une puissance de traitement importante.
Le travail de reconnaissance d’images avec l’intelligence artificielle est un problème de recherche de longue date dans le de la vision par ordinateur domaine . Alors que différentes méthodes pour imiter la vision humaine ont évolué, l'objectif commun de la reconnaissance d'images est la classification des objets détectés en différentes catégories (déterminant la catégorie à laquelle appartient une image). C'est pourquoi nous l'appelons également reconnaissance d'objets d'apprentissage profond .
Au cours des dernières années, l'apprentissage automatique, en particulier la technologie d'apprentissage profond , a remporté de grands succès dans de nombreuses tâches de vision par ordinateur et de compréhension d'images
. Ainsi, les méthodes de reconnaissance d’images par apprentissage
profond obtiennent les meilleurs résultats en termes de performances
(images calculées par seconde/FPS) et de flexibilité. Plus loin dans
cet article, nous aborderons les algorithmes d’apprentissage en
profondeur et les modèles d’IA les plus performants pour la
reconnaissance d’images.
Signification et définition de la reconnaissance d'images IA
Dans le domaine de la vision par ordinateur, des termes tels que segmentation , classification , reconnaissance et détection d'objets sont souvent utilisés de manière interchangeable et les différentes tâches se chevauchent. Bien que cela ne pose pratiquement aucun problème, les choses deviennent confuses si votre flux de travail vous oblige à effectuer une tâche particulière spécifiquement.
Reconnaissance d'images vs vision par ordinateur
Les termes reconnaissance d’image et vision par ordinateur sont souvent utilisés de manière interchangeable mais sont différents. La reconnaissance d'images est une application de la vision par ordinateur qui nécessite souvent plusieurs tâches de vision par ordinateur, telles que la détection d'objets, l'identification d'images et la classification d'images.

Reconnaissance d'images et localisation d'objets
La localisation d'objets est un autre sous-ensemble de la vision par ordinateur souvent confondu avec la reconnaissance d'images. La localisation d'objets fait référence à l'identification de l'emplacement d'un ou plusieurs objets dans une image et au dessin d'un cadre de délimitation autour de leur périmètre. Cependant, la localisation d'objets n'inclut pas la classification des objets détectés.
Reconnaissance d'images et détection d'images
Les termes reconnaissance d’image et détection d’image sont souvent utilisés à la place l’un de l’autre. Il existe cependant des différences techniques importantes.
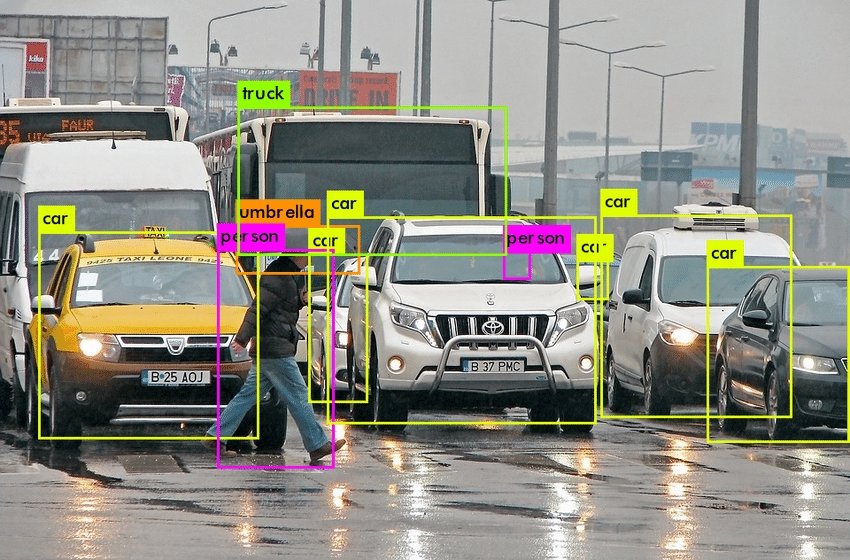
La détection d'image consiste à prendre une image en entrée et à trouver divers objets à l'intérieur. Un exemple est la détection de visage, où les algorithmes visent à trouver des modèles de visage dans les images (voir l'exemple ci-dessous). Lorsque nous traitons strictement de détection, nous ne nous soucions pas de savoir si les objets détectés sont significatifs d'une manière ou d'une autre.
Le but de la détection d'image est uniquement de distinguer un objet d'un autre pour déterminer combien d'entités distinctes sont présentes dans l'image. Ainsi, des cadres de délimitation sont dessinés autour de chaque objet distinct.
D'autre part, la reconnaissance d'images consiste à identifier les objets d'intérêt au sein d'une image et à reconnaître à quelle catégorie ou classe ils appartiennent.

Comment fonctionne la reconnaissance d’images IA ?
Utiliser la vision par ordinateur traditionnelle
L'approche conventionnelle de vision par ordinateur pour la reconnaissance d'images est une séquence (pipeline de vision par ordinateur) de filtrage d'images, de segmentation d'images , d'extraction de caractéristiques et de classification basée sur des règles.
Cependant, l’ingénierie de tels pipelines nécessite une expertise approfondie en traitement d’image et en vision par ordinateur, beaucoup de temps de développement et de tests, ainsi qu’un ajustement manuel des paramètres. En général, les systèmes traditionnels de vision par ordinateur et de reconnaissance d'images basés sur les pixels sont très limités en termes d'évolutivité ou de capacité à les réutiliser dans différents scénarios/emplacements.
Utiliser l'apprentissage automatique et l'apprentissage profond
La reconnaissance d'images avec l'apprentissage automatique, quant à elle, utilise des algorithmes pour apprendre des connaissances cachées à partir d'un ensemble de données d'échantillons bons et mauvais (voir apprentissage supervisé ou non supervisé ). La méthode d’apprentissage automatique la plus populaire est l’apprentissage profond, dans lequel plusieurs couches cachées d’un réseau neuronal sont utilisées dans un modèle.

L’introduction de l’apprentissage profond, associée à un matériel d’IA et à des GPU puissants, a permis de grandes avancées dans le domaine de la reconnaissance d’images. Grâce à l'apprentissage profond, à la classification d'images et aux algorithmes de reconnaissance faciale des réseaux neuronaux profonds, en temps réel vous obtenez des performances supérieures au niveau humain et une détection d'objets .
Il n’en demeure pas moins qu’il est difficile d’équilibrer performances et efficacité informatique. Le matériel et les logiciels dotés de modèles d'apprentissage profond doivent être parfaitement alignés afin de surmonter les problèmes de coûts liés à la vision par ordinateur .
Par conséquent, la possibilité de toujours utiliser l’algorithme le plus récent a des implications directes en termes de coûts : l’algorithme le plus puissant et le plus efficace nécessite un matériel plusieurs fois moins cher ou atteint des performances plusieurs fois supérieures sur un matériel équivalent par rapport aux algorithmes existants.
Progrès de l’algorithme de vision par ordinateur
Au fil des années, nous avons constaté des progrès significatifs dans les performances des algorithmes de vision par ordinateur :
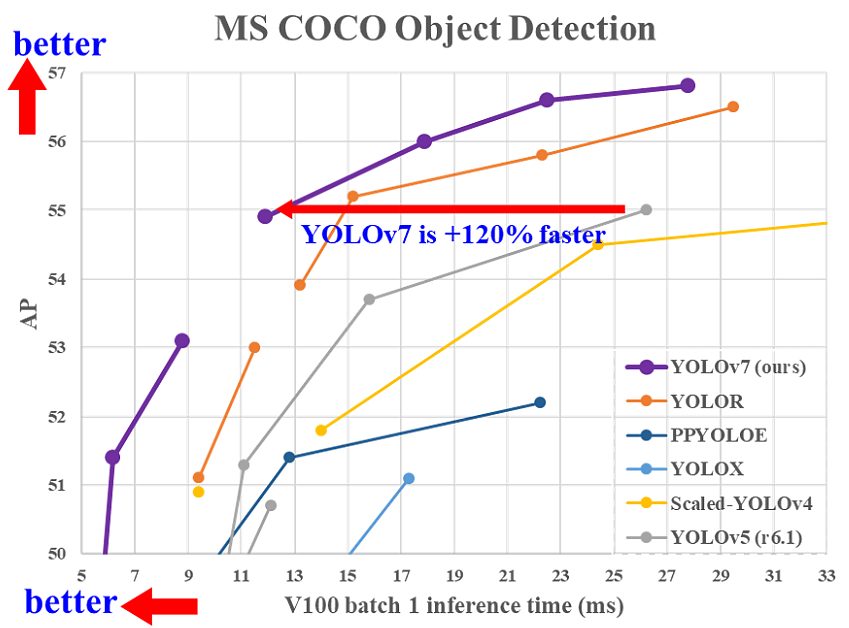
- En 2017, l' algorithme Mask RCNN était le détecteur d'objets en temps réel le plus rapide du benchmark MS COCO , avec un temps d'inférence de 330 ms par image.
- En comparaison, l' algorithme YOLOR publié en 2021 atteint des temps d'inférence de 12 ms sur le même benchmark, surpassant les populaires algorithmes d'apprentissage en profondeur YOLOv4 et YOLOv3 .
- Et en juillet 2022, l’ algorithme YOLOv7 a même largement dépassé YOLOR en termes de vitesse et de précision.
- En 2023, un nouveau modèle YOLOv8 a atteint des performances de pointe en matière de détection d'objets en temps réel . Le puissant modèle Segment Anything marque le SOTA actuel pour la segmentation d'images.
- Début 2024, YOLOv9 est sorti, une nouvelle architecture pour la formation de modèles d'IA de détection d'objets.
Comparé à l'approche traditionnelle de vision par ordinateur dans le traitement d'images il y a 20 ans, l'apprentissage profond nécessite uniquement une connaissance technique d'un outil d'apprentissage automatique, et non une expertise dans des domaines spécifiques de la vision industrielle pour créer des fonctionnalités artisanales. Alors que les premières méthodes nécessitaient d’énormes quantités de données d’entraînement, les nouvelles méthodes d’apprentissage en profondeur ne nécessitaient que des dizaines d’échantillons d’apprentissage.
Cependant, l'apprentissage profond nécessite un étiquetage manuel des données pour annoter les bons et les mauvais échantillons, un processus appelé annotation d'image . Le processus d’apprentissage à partir de données étiquetées par des humains est appelé apprentissage supervisé. Le processus de création de telles données étiquetées pour former des modèles d’IA nécessite un travail humain fastidieux, par exemple pour étiqueter les images et annoter les situations de circulation standard pour les véhicules autonomes.
Le processus des systèmes de reconnaissance d'images IA
Quelques étapes sont à la base du fonctionnement des systèmes de reconnaissance d’images.
- Ensemble de données avec données d'entraînement
Les modèles de reconnaissance d'images nécessitent des images étiquetées comme données d'entraînement (vidéo, image, photo, etc.). Les réseaux de neurones ont besoin de ces images d’entraînement provenant d’un ensemble de données acquises pour créer une perception de l’apparence de certaines classes.
Par exemple, un modèle de reconnaissance d'image qui détecte différentes poses ( modèle d'estimation de pose ) aurait besoin de plusieurs instances de différentes poses humaines pour comprendre ce qui rend les poses uniques les unes des autres. - Formation des réseaux de neurones pour la reconnaissance d'images IA en ligne
Les images de l'ensemble de données créé sont introduites dans un algorithme de réseau neuronal . Il s’agit de l’aspect profond ou apprentissage automatique de la création d’un modèle de reconnaissance d’image. La formation d'un algorithme de reconnaissance d'images permet à la reconnaissance d'images de réseaux neuronaux convolutifs d'identifier des classes spécifiques. bien testés Plusieurs frameworks sont aujourd’hui largement utilisés à ces fins. - Tests de modèles d'IA
Le modèle entraîné doit être testé avec des images qui ne font pas partie de l'ensemble de données d'entraînement. Ceci est utilisé pour déterminer la convivialité, les performances et la précision du modèle. Par conséquent, environ 80 à 90 % de l’ensemble complet de données d’images est utilisé pour la formation du modèle. Les données restantes sont réservées aux tests sur modèle. Les performances du modèle sont mesurées sur la base d'un ensemble de paramètres qui indiquent le pourcentage de confiance de précision par image de test, les identifications incorrectes, etc. Lisez notre article sur la façon d' évaluer les performances du modèle en apprentissage automatique.

Reconnaissance d'images IA avec apprentissage automatique
Avant que les GPU (Graphical Processing Unit) ne deviennent suffisamment puissants pour prendre en charge les tâches de calcul massivement parallèles des réseaux de neurones , les algorithmes d'apprentissage automatique traditionnels constituaient la référence en matière de reconnaissance d'images.
Modèles d'apprentissage automatique de reconnaissance d'images
Examinons les trois modèles d'apprentissage automatique de reconnaissance d'images les plus populaires.
- Machines à vecteurs de support
Les SVM fonctionnent en créant des histogrammes d'images contenant les objets cibles et également d'images qui n'en contiennent pas. L'algorithme prend ensuite l'image test et compare les valeurs de l'histogramme entraînées avec celles des différentes parties de l'image pour vérifier les correspondances. - Sac de modèles de fonctionnalités
Les modèles de sac de fonctionnalités tels que la transformation de caractéristiques invariantes d'échelle (SIFT) et les régions extrêmes stables au maximum (MSER) fonctionnent en prenant l'image à numériser et un exemple de photo de l'objet à trouver comme référence. Le modèle essaie ensuite de faire correspondre les pixels des caractéristiques de l'échantillon de photo à différentes parties de l'image cible pour voir si des correspondances sont trouvées. - Algorithme de Viola-Jones
Algorithme de reconnaissance faciale largement utilisé avant CNN (Convolutional Neural Network), Viola-Jones fonctionne en scannant les visages et en extrayant les caractéristiques qui sont ensuite transmises via un classificateur de renforcement. Ceci, à son tour, génère plusieurs classificateurs améliorés pour vérifier les images de test. Pour trouver une correspondance réussie, une image test doit générer un résultat positif pour chacun de ces classificateurs.
Modèles de reconnaissance d'images d'apprentissage profond
En reconnaissance d'images, l'utilisation de réseaux de neurones convolutifs (CNN) est également appelée reconnaissance d'images profondes. Les CNN sont inégalés par les méthodes traditionnelles d’apprentissage automatique. Non seulement les CNN sont plus rapides et fournissent les meilleurs résultats de détection en matière de reconnaissance d'images par apprentissage automatique, mais ils peuvent également détecter plusieurs instances d'un objet à partir d'une image, même si l'image est légèrement déformée, étirée ou modifiée sous une autre forme.
Dans la reconnaissance d'images approfondies, les réseaux de neurones convolutifs surpassent même les humains dans des tâches telles que la classification d'objets en catégories fines telles que la race particulière de chien ou l'espèce d'oiseau.
Les modèles d'apprentissage profond les plus populaires, tels que YOLO , SSD et RCNN, utilisent des couches de convolution pour analyser une image ou une photo numérique. Pendant l'entraînement, chaque couche de convolution agit comme un filtre qui apprend à reconnaître certains aspects de l'image avant de la transmettre à la suivante.
Un calque traite les couleurs, un autre les formes, etc. En fin de compte, un résultat composite de toutes ces couches est collectivement pris en compte pour déterminer si une correspondance a été trouvée.

Algorithmes populaires de reconnaissance d’images IA
Pour la reconnaissance d’images ou la reconnaissance de photos, quelques algorithmes sont au-dessus des autres. Bien qu’il s’agisse tous d’algorithmes d’apprentissage profond, leur approche fondamentale quant à la façon dont ils reconnaissent différentes classes d’objets varie. Jetons un coup d'œil à certains des modèles de reconnaissance d'images les plus populaires aujourd'hui :
CNN régional plus rapide (RCNN plus rapide)
Faster RCNN (Region-based Convolutional Neural Network) est le plus performant de la famille d'algorithmes de reconnaissance d'images R-CNN, notamment R-CNN et Fast R-CNN.
Il utilise un réseau de proposition de région (RPN) pour la détection des fonctionnalités ainsi qu'un Fast RCNN pour la reconnaissance d'images, ce qui en fait une mise à niveau significative par rapport à son prédécesseur (Remarque : Fast RCNN vs Faster RCNN). Faster RCNN peut traiter une image en moins de 200 ms, tandis que Fast RCNN prend 2 secondes ou plus.
Détecteur à coup unique (SSD)
Les RCNN dessinent des cadres de délimitation autour d'un ensemble proposé de points sur l'image, dont certains peuvent se chevaucher. Les détecteurs à prise unique (SSD) discrétisent ce concept en divisant l'image en cadres de délimitation par défaut sous la forme d'une grille sur différents rapports d'aspect.
Il combine ensuite les cartes de caractéristiques obtenues en traitant l'image dans différents rapports d'aspect pour gérer naturellement des objets de différentes tailles. Cela rend les SSD très flexibles, précis et faciles à entraîner. Une implémentation de SSD peut traiter une image en 125 ms.
On ne regarde qu'une fois (YOLO)
YOLO signifie You Only Look Once, et fidèle à son nom, l'algorithme traite une image une seule fois en utilisant une taille de grille fixe, puis détermine si une zone de grille contient une image ou non.
À cette fin, l'algorithme de détection d'objets utilise une métrique de confiance et plusieurs cadres de délimitation dans chaque cadre de grille. Cependant, il n'aborde pas la complexité des multiples formats d'image ou cartes de caractéristiques, et ainsi, même si cela produit des résultats plus rapidement, ils peuvent être un peu moins précis que le SSD.
Une variante légère et optimisée de YOLO appelée Tiny YOLO peut traiter une vidéo jusqu'à 244 ips ou 1 image à 4 ms.
Les autres versions populaires de YOLO incluent :
Comment appliquer des modèles de reconnaissance d'images IA
Reconnaissance d'images avec Python
Pour la reconnaissance d'images, Python est le langage de programmation de choix pour la plupart des data scientists et des ingénieurs en vision par ordinateur . Il prend en charge un grand nombre de bibliothèques spécialement conçues pour les flux de travail d'IA, notamment la détection et la reconnaissance d'images.
- Étape 1 : Pour configurer votre ordinateur pour effectuer des tâches de reconnaissance d'image Python, vous devez télécharger Python et installer les packages nécessaires à l'exécution des tâches de reconnaissance d'image, y compris Keras.
- Étape n°2 : Keras est une API d'apprentissage en profondeur de haut niveau pour exécuter des applications d'IA. Il fonctionne sur TensorFlow /Python et aide les utilisateurs finaux à déployer des applications d'apprentissage automatique et d'IA à l'aide d'un code facile à comprendre.
- Étape n°3 : Si votre machine ne dispose pas de carte graphique, vous pouvez utiliser des instances GPU gratuites en ligne sur Google Colab. Pour classer les animaux, il existe un ensemble de données bien étiqueté connu sous le nom de « Animaux-10 » que vous pouvez trouver sur Kaggle . L'ensemble de données est téléchargeable gratuitement.
- Étape n°4 : Une fois que vous avez obtenu l'ensemble de données en ligne de Kaggle en obtenant un jeton API, vous pouvez alors commencer à coder en Python après avoir retéléchargé les fichiers nécessaires sur Google Drive.
Pour plus de détails sur les implémentations spécifiques à la plateforme, plusieurs articles bien rédigés sur Internet vous guident étape par étape dans le processus de configuration d'un environnement pour l'IA sur votre machine ou sur votre Colab que vous pouvez utiliser.
Vous pouvez également consulter la plate-forme de reconnaissance d'images d'entreprise Viso Suite pour créer, déployer et faire évoluer des applications du monde réel sans écrire de code. Il permet d'éviter les problèmes d'intégration, d'économiser les coûts de plusieurs outils et est hautement extensible.
Entraîner un modèle personnalisé
Un modèle personnalisé pour la reconnaissance d'images est un modèle ML spécialement conçu pour une tâche de reconnaissance d'images spécifique. Cela peut impliquer l'utilisation d'algorithmes personnalisés ou des modifications d'algorithmes existants pour améliorer leurs performances sur les images (par exemple, recyclage du modèle).
Bien que les modèles pré-entraînés fournissent des algorithmes robustes entraînés sur des millions de points de données, il existe de nombreuses raisons pour lesquelles vous souhaiterez peut-être créer un modèle personnalisé pour la reconnaissance d'images. Par exemple, vous pouvez disposer d’un ensemble de données d’images très différent des ensembles de données standard sur lesquels les modèles de reconnaissance d’images actuels sont formés.
Dans ce cas, un modèle personnalisé peut être utilisé pour mieux connaître les caractéristiques de vos données et améliorer les performances. Alternativement, vous travaillez peut-être sur une nouvelle application dans laquelle les modèles de reconnaissance d'images actuels n'atteignent pas la précision ou les performances requises.
La création d'un modèle personnalisé basé sur un ensemble de données spécifique peut être une tâche complexe et nécessite une collecte de données et une annotation d'images de haute qualité . Cela nécessite une bonne compréhension de l’apprentissage automatique et de la vision par ordinateur. Découvrez notre article sur la façon d'évaluer les performances des modèles d'apprentissage automatique .

API de reconnaissance d'images (Cloud) vs Edge AI
Les API offrent un moyen simple d'effectuer une reconnaissance d'image en appelant un service API basé sur le cloud tel qu'Amazon Rekognition (AWS Cloud). De même, il est facile d'utiliser une API pour reconnaître des objets dans des images avec l'API Google Vision (Google Cloud) pour des tâches telles que la détection d'objets ou de visages, la reconnaissance de texte ou la reconnaissance d'écriture manuscrite.
Une API de reconnaissance d'images telle que l'API de détection d'objets de TensorFlow est un outil puissant permettant aux développeurs de créer et de déployer rapidement un logiciel de reconnaissance d'images si le cas d'utilisation permet le déchargement de données (envoi de visuels à un serveur cloud). L'utilisation d'une API pour la reconnaissance d'images permet de récupérer des informations sur l'image elle-même ( classification d'image ou identification d'image) ou sur les objets contenus ( détection d'objet ).
purement basées sur le cloud Les API de vision par ordinateur sont utiles pour le prototypage et les solutions à plus petite échelle. Ces solutions permettent le déchargement des données (confidentialité, sécurité, légalité ), ne sont pas critiques (connectivité, bande passante, robustesse), et ne sont pas en temps réel (latence, volume de données, coûts élevés ). Pour surmonter les limites des solutions purement cloud, les tendances récentes en matière de reconnaissance d'images se concentrent sur l'extension du cloud en tirant parti de l'Edge Computing avec l'apprentissage automatique sur l'appareil .
Pour savoir comment fonctionnent les API de reconnaissance d'images, laquelle choisir et les limites des API pour les tâches de reconnaissance, je vous recommande de consulter notre revue des API de vision par ordinateur les mieux payées et gratuites .
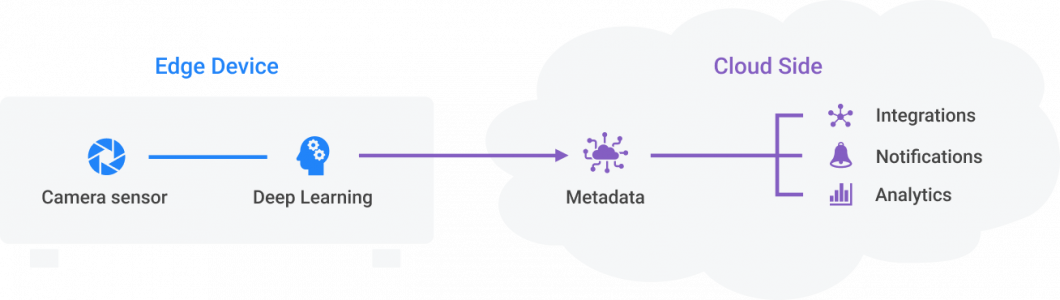
Alors que les API de vision par ordinateur peuvent être utilisées pour traiter des images individuelles, les systèmes Edge AI sont utilisés pour effectuer des tâches de reconnaissance vidéo en temps réel. Ceci est possible en déplaçant l'apprentissage automatique à proximité de la source de données ( Edge Intelligence ). Le traitement des images IA en temps réel, car les données visuelles sont traitées sans déchargement de données (téléchargement de données vers le cloud), permet des performances d'inférence et une robustesse plus élevées requises pour les systèmes de production.
Plateforme de reconnaissance d'images IA
Notre infrastructure de vision par ordinateur, Viso Suite , évite de devoir repartir de zéro et d'utiliser une infrastructure préconfigurée. Il fournit un logiciel de reconnaissance d'image open source populaire prêt à l'emploi, avec plus de 60 des meilleurs modèles pré-entraînés. Il fournit également la collecte de données, l'étiquetage des images et le déploiement sur les appareils périphériques.
Cette plate-forme de vision IA prend en charge la création et l'exploitation d'applications en temps réel, l'utilisation de réseaux de neurones pour les tâches de reconnaissance d'images et l'intégration du tout avec vos systèmes existants. Obtenez une démo ici .
À quoi sert la reconnaissance d’images IA ?
Dans tous les secteurs, la technologie de reconnaissance d’images par l’IA devient de plus en plus impérative. Ses applications apportent une valeur économique dans des secteurs tels que la santé , la vente au détail , la sécurité , l'agriculture et bien d'autres encore. Pour une liste complète des applications de vision par ordinateur, explorez les applications de vision par ordinateur les plus populaires aujourd'hui .
Application de reconnaissance d'images pour l'analyse des visages
L'analyse des visages est une application importante de reconnaissance d'images. Les méthodes modernes de ML permettent d'utiliser le flux vidéo de n'importe quel appareil photo numérique ou webcam. Dans de telles applications, le logiciel de reconnaissance d'images utilise des algorithmes d'IA pour la détection simultanée des visages, l'estimation de la pose du visage, l'alignement du visage, la reconnaissance du genre, la détection du sourire, l'estimation de l'âge et la reconnaissance du visage à l'aide d'un réseau neuronal convolutif profond.
L'analyse faciale avec vision par ordinateur consiste à analyser les médias visuels pour reconnaître l'identité, les intentions, les états émotionnels et de santé, l'âge ou l'origine ethnique. Certains outils de reconnaissance de photos pour les réseaux sociaux visent même à quantifier les niveaux d’attractivité perçue grâce à un score.
D'autres tâches liées à la reconnaissance faciale impliquent l'identification d'images faciales, la reconnaissance faciale et la vérification faciale, qui impliquent des méthodes de traitement de la vision pour rechercher et faire correspondre un visage détecté avec des images de visages dans une base de données. Les méthodes de reconnaissance par apprentissage profond peuvent identifier les personnes sur des photos ou des vidéos même lorsqu'elles vieillissent ou dans des situations d'éclairage difficiles.
L'une des bibliothèques de logiciels open source les plus populaires pour créer des applications de reconnaissance faciale IA s'appelle DeepFace , qui peut analyser des images et des vidéos. Pour en savoir plus sur l’analyse faciale avec l’IA et la reconnaissance vidéo, consultez notre sur la reconnaissance faciale approfondie . article
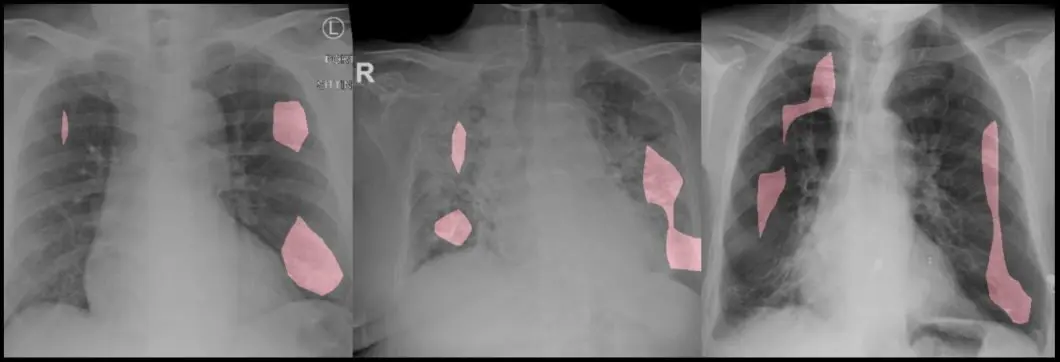
Reconnaissance d'images pour l'analyse d'images médicales
La technologie de reconnaissance visuelle est courante dans le secteur des soins de santé pour permettre aux ordinateurs de comprendre les images régulièrement acquises tout au long du traitement. L’analyse d’images médicales devient un sous-ensemble très rentable de l’intelligence artificielle.
Par exemple, il existe de nombreux travaux concernant l’identification du mélanome, un cancer de la peau mortel. Un logiciel de reconnaissance d'images par apprentissage profond permet de surveiller les tumeurs au fil du temps, par exemple pour détecter des anomalies dans les analyses du cancer du sein .
En savoir plus sur les applications de la reconnaissance d'images dans le domaine de la santé
Reconnaissance d'images pour la surveillance des animaux
Les systèmes de reconnaissance d’images agricoles utilisent de nouvelles techniques pour identifier les espèces animales et leurs actions. Le logiciel de reconnaissance d'images AI est utilisé pour la surveillance des animaux dans l'agriculture . Le bétail peut être surveillé à distance pour la détection de maladies, la détection d'anomalies, le respect des directives en matière de bien-être animal, l'automatisation industrielle, etc.
Découvrez notre guide sur les meilleures applications de la vision par ordinateur dans l'agriculture et l'agriculture intelligente .
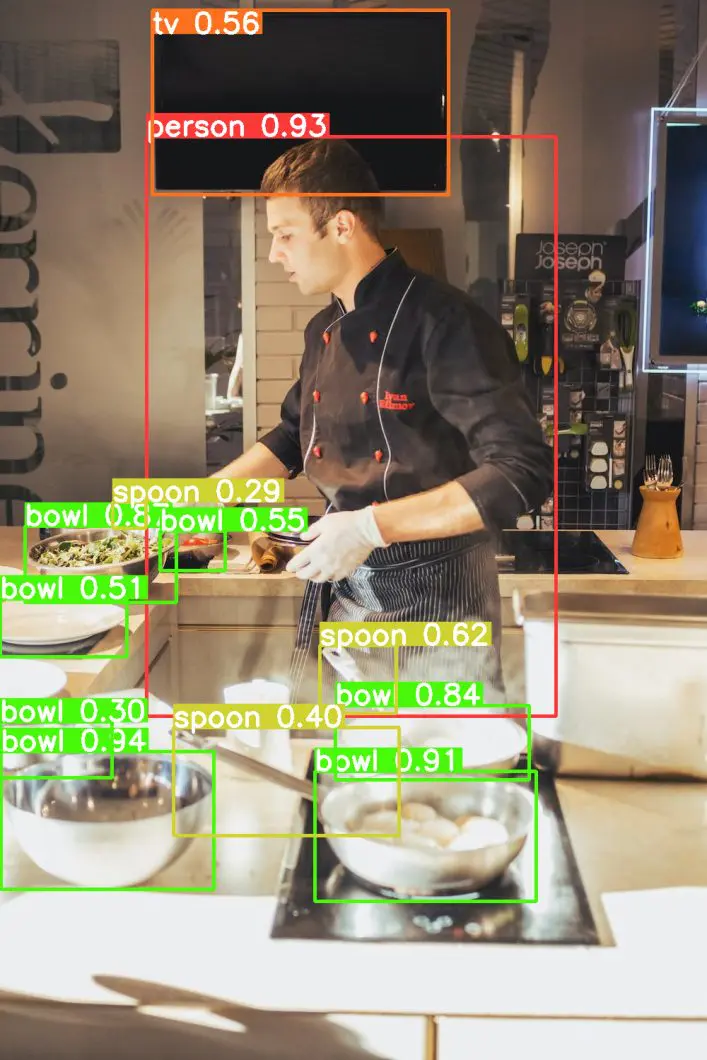
Détection de motifs et d'objets
Les technologies de reconnaissance photo et vidéo IA sont utiles pour identifier des personnes, des motifs, des logos, des objets, des lieux, des couleurs et des formes. La personnalisation de la reconnaissance d’images lui permet d’être utilisée conjointement avec plusieurs logiciels. Par exemple, un programme de reconnaissance d'images spécialisé dans la détection de personnes dans une image vidéo est utile pour compter les personnes populaire , une application de vision par ordinateur dans les magasins de détail.
Vous pouvez en apprendre davantage sur la reconnaissance de formes de pointe et l’apprentissage automatique dans les images sur notre récent blog.
Identification automatisée des images des installations
L'identification des plantes basée sur l'image a connu un développement rapide et est déjà utilisée dans des cas d'utilisation en recherche et en gestion de la nature. Un article de recherche récent a analysé la précision de l’identification des images pour déterminer la famille des plantes, les formes de croissance, les formes de vie et la fréquence régionale. L'outil effectue une reconnaissance de recherche d'images à l'aide de la photo d'une plante avec un logiciel de correspondance d'images pour interroger les résultats sur une base de données en ligne.
Les résultats indiquent une précision élevée de la reconnaissance de l’IA. 79,6 % des 542 espèces sur environ 1 500 photos ont été correctement identifiées, tandis que la famille végétale a été correctement identifiée pour 95 % des espèces.
Reconnaissance d'images alimentaires
La reconnaissance d'images par apprentissage profond de différents types d'aliments est utile pour l'évaluation diététique assistée par ordinateur . Par conséquent, des applications logicielles de reconnaissance d’images se développent pour améliorer la précision des mesures actuelles de l’apport alimentaire. Pour ce faire, ils analysent les images alimentaires capturées par les appareils mobiles et partagées sur les réseaux sociaux. Par conséquent, une application de reconnaissance d’images effectue une reconnaissance de formes en ligne dans les images téléchargées par les étudiants.
Reconnaissance de recherche d'images
La reconnaissance de recherche d'images, ou recherche visuelle, utilise des caractéristiques visuelles apprises à partir d'un réseau neuronal profond pour développer des méthodes efficaces et évolutives de récupération d'images. L'objectif des cas d'utilisation de la recherche visuelle est d'effectuer une récupération d'images basée sur le contenu pour les applications en ligne de reconnaissance d'images.
Les chercheurs ont développé un dictionnaire visuel à grande échelle à partir d’un ensemble de fonctionnalités de réseau neuronal pour résoudre ce problème complexe.
Applications typiques de reconnaissance d'images IA
- Application n°1 : Reconnaissance d'images industrielles pour la détection de défauts et l'analyse prédictive dans la fabrication
- Application n°2 : Détection automatisée des intrusions dans les systèmes distribués de sécurité et de surveillance
- Application n°3 : Systèmes de reconnaissance d'images pour l'analyse de la corrosion et des fuites la détection dans le pétrole et le gaz
- Application n°4 : Logiciel de reconnaissance de photos pour la détection des fraudes en assurance
- Application n°5 : Comptage de personnes en temps réel et analyse des foules dans les villes intelligentes
- Application n°6 : Application de reconnaissance d'images pour la détection d'armes (couteaux, fusils)
- Application n°7 : Voitures et drones autonomes pour une navigation automatisée.

En savoir plus sur les sujets connexes à la reconnaissance d'images par l'IA
Actuellement, les réseaux de neurones convolutifs (CNN) tels que ResNet et VGG sont des réseaux de neurones de pointe pour la reconnaissance d'images. Dans les recherches actuelles sur la vision par ordinateur, les Vision Transformers (ViT) ont montré des résultats prometteurs dans les tâches de reconnaissance d'images. Les modèles ViT atteignent la précision des CNN avec une efficacité de calcul 4 fois supérieure.
Pour plus d’informations sur la vision par ordinateur, explorez les sujets connexes sur la vision par ordinateur sur notre blog :
- En savoir plus sur l'analyse vidéo avec les flux vidéo en direct
- Explorez les applications de vision par ordinateur populaires
- Détection d'objets - un guide du débutant
- Qu’est-ce que le traitement du langage naturel ? Un guide de la PNL
- D'Amazon Rekognition aux API de reconnaissance faciale : les 10 meilleures API de vision par ordinateur
Utiliser des modèles d'IA pour créer un système de reconnaissance d'images d'IA
Nous propulsons Viso Suite , une plateforme logicielle d'apprentissage automatique de reconnaissance d'images qui aide les leaders du secteur à mettre en œuvre toutes leurs applications de vision IA considérablement plus rapidement. Nous fournissons une solution et une infrastructure de niveau entreprise pour fournir et maintenir des systèmes robustes de reconnaissance d’images en temps réel.
Viso fournit la plateforme de vision d'IA la plus complète et la plus flexible, avec une approche « construire une fois – déployer n'importe où ». Utilisez les flux vidéo de n’importe quelle caméra (caméras de surveillance, CCTV, webcams, etc.) avec les modèles d’IA les plus récents et les plus puissants prêts à l’emploi.
- Viso Suite fournit une solution tout-en-un pour créer, déployer et surveiller des systèmes de vision par ordinateur.
- Utilisez une programmation visuelle, des interfaces simplifiées et une infrastructure automatisée pour offrir une vision par ordinateur 10 fois plus rapide.
- Gérez les appareils de périphérie et déployez des modèles personnalisés ou des modèles de reconnaissance d'image pré-entraînés en un seul clic.
- Évitez les problèmes d'intégration et l'écriture de code à partir de zéro ; utiliser des applications prédéfinies .